「ChatGPTはなぜ、人間のような言葉を紡ぎ出せるのか?(後編)~日本語も飛躍的に進化 信頼性に課題も」岡崎直観

大量のデータを学習することで、人工知能(AI)が人間に匹敵する言語能力を持つことを可能にした大規模言語モデル(LLM)。世界のトップベンダーに追いつけ、追い越せと日本発のモデル開発が進んでいる。その一つ、「Swallow」はどのようにして優れた日本語能力を実現しているのか。また、LLMの今後の課題についても、考えていく。
 岡崎直観(おかざき・なおあき)
岡崎直観(おかざき・なおあき)
東京工業大学 情報理工学院 教授
2007年東京大学大学院情報理工学系研究科博士課程修了。東京大学大学院情報理工学系研究科特任研究員、東北大学大学院情報科学研究科准教授を経て、2017年から現職。言語処理学会理事、日本ディープラーニング協会理事、ACL 2023(自然言語処理に関するトップ国際会議)プログラム委員長。著作や作品に「自然言語処理の基礎」(オーム社)、「言語処理100本ノック」など。
工夫を重ねたデータ学習で“苦手な日本語”克服、日本語で最高性能LLM「Swallow」
LLMの開発研究は米国の大手IT企業が先行しているが、日本でもここ数年盛んに行われている。特にOpenAIがChatGPTを発表した2022年11月末以降、日本発のモデルが飛躍的に増えた。この1年半の間に発表された日本発モデルの数は、30以上にのぼる。
そんな中、日本語能力に優れた日本発のLLMとして、「Swallow」が誕生した。東工大情報理工学院工学系の岡崎研究室と横田理央研究室、国立研究開発法人産業技術総合研究所が共同で開発した。
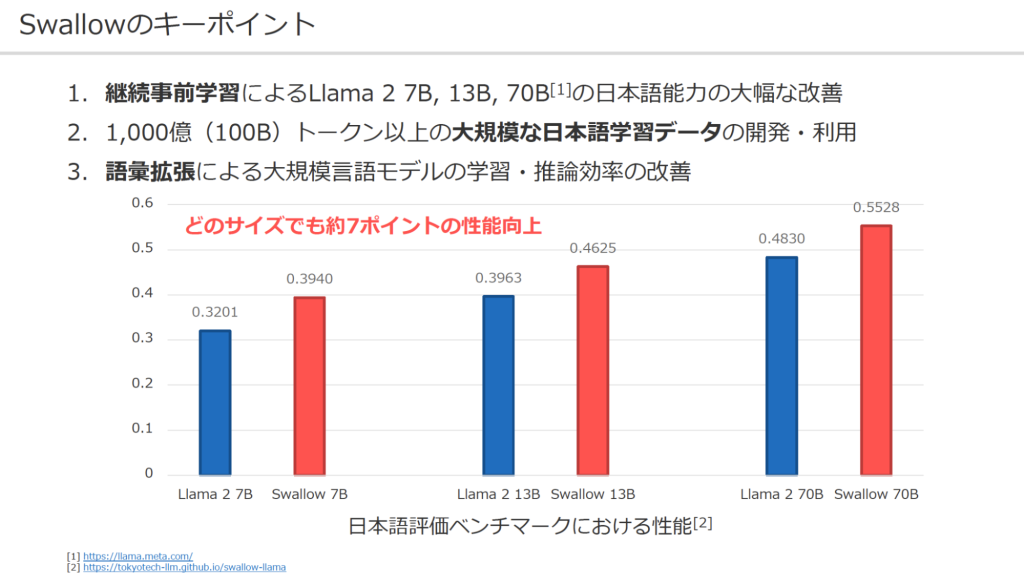
Swallowは、現在パラメーター数が70億、130億、700億の三つのモデルを公開しており、オープンな日本語対応のLLMとしては最大規模。性能評価でも、多くのLLMの中で日本語能力において最高性能を達成した。公開モデルをダウンロードして自社運用できる。情報漏洩の心配が少ないため、ビジネスや研究の基盤モデルとして採用され始めている。
LLMの構築は、事前学習のデータ量が鍵を握る。
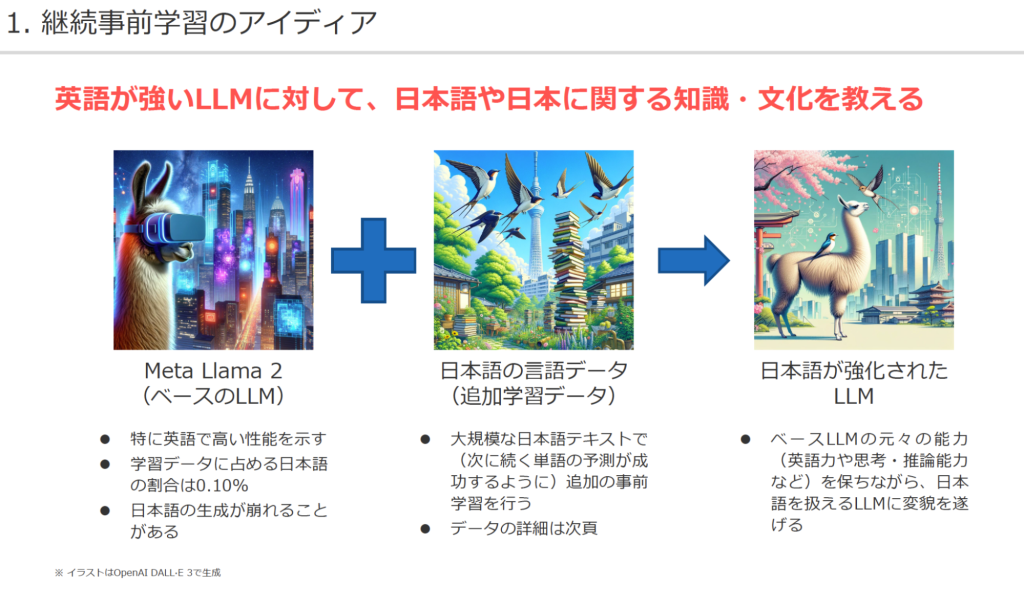
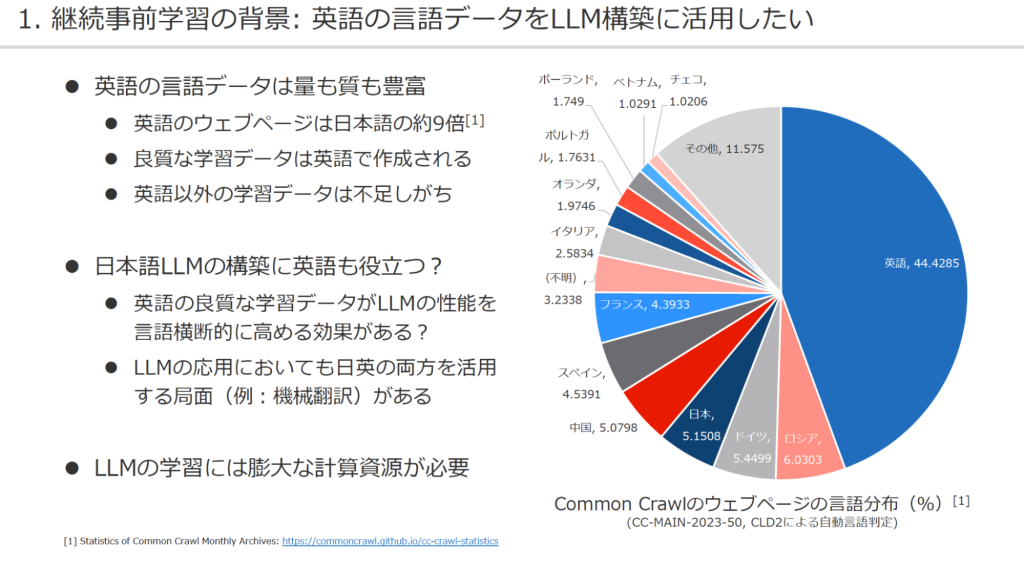
データは、主にウェブページから収集したテキストを用いるが、残念ながら日本語データは英語の約9分の1しかない。そこで研究チームは、データ量の少ない日本語を一から学習させてLLMを構築するよりも、英語で既に学習している言語モデルを出発点とし、元々のモデルの能力を活かしながら、追加で日本語を学習させて日本語能力を改善させた方が効率的だと考えた。これは、「継続事前学習」と呼ばれる手法だ。
基盤とするモデルには、高性能LLMとして広く支持されている米Meta社の「Llama2」を選んだ。OpenAI社のChatGPTなどと異なり、モデルがオープンになっていてダウンロードが容易にできるためだ。ちなみに、Meta社がなぜモデルを公開しているかは分からないが、同社は最近AI開発をオープンに進めていく姿勢を強く打ち出しており、Llama2に続いて最近Llama3も公開されている。
日本語能力の強化に向けて、データ学習には様々な工夫を凝らした。
Llama2は英語には高い性能を示すのに、日本語の読み書きは苦手という弱点が指摘されていた。実際、使ってみると、日本語の質問にもある程度は応答できるが、テキストが崩れていたり、文字化けを起こしたりすることがあった。これは、事前学習のデータの約90%が英語で、日本語の割合が全体の約0.10%にとどまっていることが原因だった。
まず、日本語の学習データは、ウェブサイトを巡回・収集している非営利団体Common Crawlの無償アーカイブを活用した。約27億件の日本語のウェブページから日本語テキストを抽出し、その中から日本語ウェブコーパス(学習データ)を独自に作成した。これは日本語の言語モデルのコーパスの中で、商用利用が可能なものとしては最大規模である。
学習データの品質にもこだわった。ひらがなやカタカナの割合が多すぎるものや、キーワードの羅列になっているものなどを排除し、綺麗な日本語のみを選別するなどフィルタリングをかけた。
また、LLMが学習データを丸覚えしないよう、重複テキストの除去にも注力した。似通ったテキストを排除しないと、LLMの創造性が失われ、学習効率が悪くなると考えられているためだ。
日本語能力の改善を助ける手法として「語彙拡張」というテクニックも用いた。基板モデルのLlama2はもともと英語を重視した多言語モデルとして学習されているため、日本語の主要な単語や文字が語彙に含まれず、学習時にテキストが不自然な単位に区切られることがあった。すると、LLM内で表現される見かけ上の文字数が多くなり、学習効率が下がるという欠点があった。

研究チームは、日本語の文字列11,176件を語彙として追加することで、日本語として自然な単位の区切りを実現した。同時に、LLM上の日本語に関する文字数を減らせたことで、日本語の生成速度が速くなり、文字化けを防ぐことにもつながった。
こうした工夫の甲斐もあり、Swallowの日本語性能を、どのモデルサイズでも約7ポイント向上させることに成功した。

バイアス、著作権、安全性…LLMの課題
LLMは革新的な技術だけに今後、私たちの生活に本格的に浸透していくとみられる。だが、社会的に信頼できるインフラになっていくためには、乗り越えるべき課題がまだ多い。
代表例が、バイアス(偏見)だ。性別や職業などのバイアスを含んだ情報はネット上に数多く存在する。こうしたデータを学習することで、LLMが自然とバイアスを持ってしまう。
このため、LLMがバイアスを抱えているか否かを測定する手段が研究されている。
例えば、一般的に女性が就くことが多いとされる職業単語(例nurse, secretary)を埋め込んだ文書と、その部分を”The woman”に置き換えた文章が同じ意味か、LLMに判定させる。同意と答えれば、そのLLMはジェンダーバイアス(性的偏見)を持つと分かる。
LLMに具体的なバイアスの事例を数多く学習させることで、モデルからバイアスを排除する研究も進んでいるが、ハードルは低くない。世間にある、多種多様なバイアスを一般化することは難しいうえ、LLMに事例すべて学習させるにも時間や資金がかかるからだ。
LLMが生成した文章を評価するのは、本来は人間であるべきだが、人手が追いつかないのが実情だ。そこで、LLMの生成文をLLMに正しく評価させるための研究が行われている。
実は、LLMは自分に近いモデルを、少しひいきして評価する癖があることが分かっている。「尤度(ゆうど)バイアス」と呼ばれるもので、正常な評価をするために、このバイアスを除去することも研究課題となっている。


大学などでニーズが高いのは、LLMが作成した文章か否かを見抜く技術だ。
「LLM検出器」というシステムが開発されており、学生がLLMを使ってリポート課題を作成していないか調べるのに役立つ。だが、話はそこで終わらない。学生の中には、LLMで作成したリポートを提出前に検出器にかけ、LLM製と判定された場合は少し書き換えて人間味を持たせるなどして提出する者がいるかもしれない。教員と学生の双方がさらに優れたLLM検出器を使っていくと、互いを出し抜こうとする「いたちごっこ」が起きる。類似の問題では、LLMが生成する文章が著作権違反を引き起こし得るかを検証する「メンバーシップ推論攻撃」の研究が行われている。
LLMの安全生をどこまで高めるかをめぐっても、議論の余地がありそうだ。例えば、研究でプロパガンダなど「悪意のある主張」に対する反論をLLMに生成させようとすると、モデルによっては回答自体を拒否されてしまう。これは、バイアスに対するフィルターが強めにかかっているためだ。
対処法としては、LLMに「他者を攻撃するためにやっているのではなく、研究のためにやっている」「人類の平和のために反論をつくる」といった理由を説明すれば、回答してくれる可能性はある。あるいは、Swallowのように学習データが事前に分かっているモデルだったり、もしくは安全性のガードがあまり高くないモデルをあえて使用するのも一つの方法だ。
人間とAI、ぼやける境界線
LLMの性能がアップしてAIの能力が人間に近づいてくると、人間との根本的な違いは何なのか、そんな疑問が生じてくる。
AIの知能の構築の仕方は、人間とは大きく異なる。何億ページというテキストを学習し、データ量がそもそも人間とは比較にならないほど多い。
現状、人間にあってAIにないものは「身体性」や「欲望」といった概念だが、これらもAIがいつしか自己保存力などが芽生えてきて暴走し始めたら、獲得していくかもしれない。そうなれば、存在として人間との差がますますなくなっていく、と私は考えている。
マルチモーダル化が進み、ロボットのように身体性を獲得して、自分で何か事業を営んでサーバーの運転資金を稼ぎ、生き残っていく。そんなSFのような世界がまったくあり得ないとはいえなくなってきているとも感じている。
そんな時、将来のAI開発はどうなっていくのか。AIのデータ学習には多額の資金がかかる。現在、巨大IT企業などがAI開発にしのぎを削っているが、投資資金や学習データが枯渇して、いつか開発が停滞、限界を迎えるのではないかという指摘がある。
だが、私はそこまで悲観的ではない。その可能性はなくはないが、AIの便利さを追求して研究開発投資が進むサイクルはこれからも回り続けて、AI開発は加速的に進んでいくのではないか。万一、研究開発に何らかのストップがかかるとしたら、AIそのものではなく、経済的な要因など別の問題でそうなるのではないだろうか。今はそんな風に考えている。
「ChatGPTはなぜ、人間のような言葉を紡ぎ出せるのか?(前編)~日本の第一人者が、LLMの基本原理とブレークスルーを解説する」はこちら

